Tip of the Week 112 emplace与push_back
“我们越少使用我们的力量,它就会越强大。” —— 托马斯 杰克逊
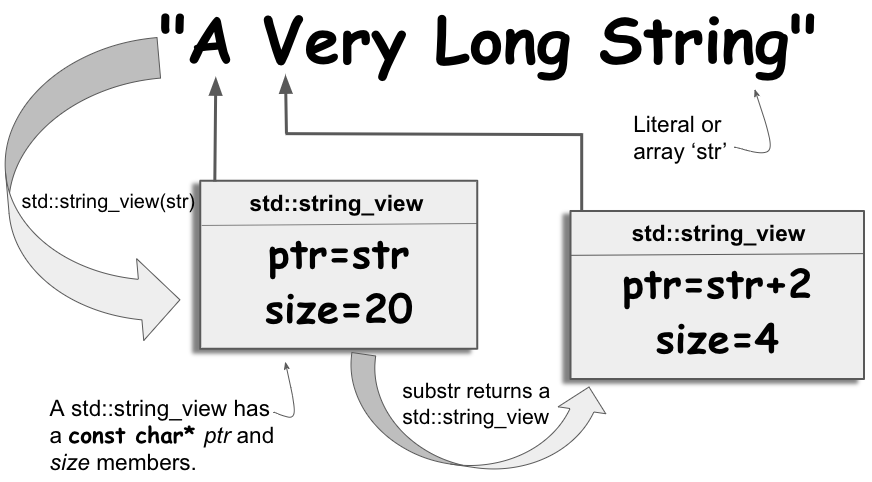
正如你所知(如果不知道,参见TotW 65)
正如你所知道的,C++11引入了一种强大的新方法来讲条目插入到容器中:emplace方法。这些可以让使用任何对象的构建函数在一个容器内原地构建一个对象。这包含移动和拷贝构造函数,因此在你可以使用push或者insert方法时,你可以使用emplace方法代替,而不需要其他修改。
1 | std::vector<string> my_vec; |
这产生一个明显的问题:你应该用哪一个好?我们是否应该放弃push_back()和insert(),并且一直使用emplace方法吗?
让我通过问另外一个问题来回答这个问题:这两行代码做了什么?
1 | vec1.push_back(1<<20); |
第一行相当简单:它将数字1048576天假到vector的末尾。然而,第二行就不那么清晰了。在不知道vecotr类型的情况下,我们不知道它会调用什么构造函数,因此我们无法正真说出那行代码做了什么。例如,如果vec2是一个std::vector,那么哪行仅仅添加到末尾,就像第一行一样,但是如果vec2是std::vector<std::vector>,那么第二行会构造一个超过百万个元素的vector,在该进程中分配几兆字节的内存。
因此,如果你有同样的参数时,在push_back和emplace_back之间进行选择,如果你选择push_back,那么你的代码会更具有可读性,因为push_back更确切的表现了你的意图。选择push_back也更加安全:假定你有一个std::vector<std::vector>,并且你想附加一个数据到第一个vector,但是你偶然忘记了下标。如果你写my_vec.push_back(2<<20),那么你会得到一个编译错误,然后你会快速发现问题。另一方面,如果你编写my_vec.emplace(2<<2),代码将成功编译,并且知道运行前,你也不会注意到任何问题。
现在,当涉及隐式转换时,emplace_back()确实比push_back()快一些。例如,在我们要开始的代码中,my_vec.push_back(”foo”)从一个字符串字面量构造一个临时string,然后将string移动进容器中,然而emplace_back(”foo”)则直接在容器中构造string,避免了额外的移动。对于消耗更大的类型,这可能是用emplace_back()替代push_back()的一个原因,尽管存在可读性和安全性上的代价,但是情况可能并非如此。通常性能差异并不那么重要。与往常一样,经验法则是你应该避免对代码进行不够安全和不够清晰的“优化”,除非性能优势大到需要在你的应用程序基准测试中显示出来。
所以一般来说,如果push_back()和emplace_back()都使用相同的参数,那么你应该优先选择push_back(),对于insert()和emplace()也是如此。