
C/C++开发者代码优化终极指南
C/C++开发者代码优化终极指南
优化意味着调整代码,使 CPU、内存子系统和编译器能够高效执行
引言优化意味着调整代码,使 CPU、内存子系统和编译器能够高效执行——不改变逻辑,而是减少运行所需的周期、分配和停顿。
🎯 核心目标:让代码跑得更快、占用更少内存、响应更及时!
核心优化策略1. 减少执行时间123456789101112131415161718// ❌ 每次调用都计算for (int i = 0; i < N; ++i) { double angle = i * 2 * M_PI / N; // 每次计算 result[i] = std::sin(angle);}// ✅ 预计算常量const double TWO_PI = 2 * M_PI;for (int i = 0; i < N; ++i) { double angle = i * TWO_PI / N; // 使用常量 result[i] = std::sin(angle);}// ✅ 更好的方式:查表法static c ...

C++性能优化与效率完全指南
C++性能优化与效率完全指南
本文是 CppCon 2026 培训课程,由 Fedor Pikus 主讲,带你深入理解 C++ 性能的”秘密生活”
引言本文揭示了 C++ 性能的”秘密生活”,超越标准优化建议,探索与现代系统充分利用每个周期所需的机械亲和力。
🎯 核心观点:高效代码不必不可读!现代设计实践与硬件要求完美对齐。
课程结构第一部分:硬件现实超越”缓存友好”的理解,我们需要深入理解:
12345678910┌─────────────────────────────────────────────────────────┐│ 内存层次结构 │├─────────────────────────────────────────────────────────┤│ L1 Cache │ ~1ns │ ~32KB │ 最快,最昂贵 ││ L2 Cache │ ~4ns │ ~256KB │ ││ ...

OpenClaw 安装部署指南
OpenClaw 安装部署指南OpenClaw 是一个多通道 AI 助手网关,支持 WhatsApp、Telegram、Discord、飞书等多种消息平台。本文详细介绍如何在 macOS/Linux 系统上安装和部署 OpenClaw。
环境要求
Node.js: 22.x 或更高版本
操作系统: macOS / Linux / Windows
网络: 能够访问外部 API(用于连接 AI 服务)
安装步骤1. 安装 OpenClaw
在终端执行以下命令:
1curl -fsSL https://openclaw.ai/install.sh | bash
或者使用 npm 全局安装:
1npm install -g openclaw
在 PowerShell 中执行以下命令:
1iwr -useb https://openclaw.ai/install.ps1 | iex
或者使用 npm 全局安装:
1npm install -g openclaw
2. 运行初始化向导1openclaw onboard --insta ...

Android 启动流程详解
Android 启动流程详解Android 系统的启动是一个复杂而精密的过程,涉及多个阶段的协同工作。从按下电源键到看到桌面,整个流程可以分为以下几个关键阶段。
启动流程概览1Power On → Boot ROM → Bootloader → Kernel → Init → Zygote → SystemServer → Boot Animation
1. Boot ROM 阶段1.1 什么是 Boot ROMBoot ROM 是固化在设备 SoC 中的只读存储器,包含设备启动的第一段代码。这段代码由芯片厂商(如 Qualcomm、MediaTek、Samsung)在出厂时写入,无法修改。
1.2 Boot ROM 的主要任务
任务
说明
硬件初始化
初始化最基本的硬件(CPU、内存控制器)
安全验证
验证 Bootloader 的签名(Secure Boot)
加载 Bootloader
从存储设备(eMMC/UFS)加载 Bootloader 到内存
1.3 安全启动链1Boot ROM (信任根) → 验证 Bootloader → 验证 Kerne ...

哈希表性能分析实战
哈希表性能分析关键观点: 哈希表问题很难从 CPU profile 中发现,需要专门的profiler。
核心指标
指标
含义
阈值
Stuck bits
哈希函数熵不足
应为 0
Probe length
平均探针长度
> 0.1 表示有碰撞
Rehashes
重新哈希次数
过多说明没提前 reserve()
案例分析1. 使用 absl::Hash推荐使用 absl::Hash 而非自定义弱哈希函数:
1234// 推荐absl::flat_hash_map<Key, Value> map;// 避免自定义弱哈希
2. 为分片添加 Salt为分片哈希添加 salt,避免底部 bit 冲突:
123// 为每个分片添加不同的 saltuint64_t salt = GetShardSalt(shard_id);size_t hash = MixHash(base_hash, salt);
实践建议
提前分配: 使用 reserve() 预分配内存
选择合适类型: 优先使用 absl::flat_hash_map
监控指标: 定期检查探针长度 ...
Linux内核调试之动态追踪
本文介绍几种常用的内核动态追踪技术,对ftrace、perf及eBPF的使用方法进行案例说明。
1. 什么是动态追踪动态追踪技术,是通过探针机制来采集内核或者应用程序的运行信息,从而可以不用修改内核或应用程序的代码,就获得调试信息,对问题进行分析、定位。
通常在排查和调试异常问题时,我们首先想到的是使用GDB在程序运行路径上设置断点,然后结合命令进行分析定位;或者,在程序源码中增加新的日志,往往需要重新编译和部署。在面对偶先问题以及对时延要求严格的场景下,GDB和增加日志的方式就不能满足需求了。
动态追踪为这些问题提供了完美的方案:它既不需要停止服务,也不需要修改程序的代码;程序还按照原来的方式正常运行时,就可以分析出问题的根源。同时,相比以往的进程级跟踪方法(比如ptrace),动态追踪往往只会带来很小的性能损耗。
2. 动态追踪技术分类动态追踪的工具很多,systemtap、perf、ftrace、ssydig、eBPF等。动态追踪的事件源根据事件类型不同,主要分为三类:静态探针,动态探针以及硬件事件。
硬件事件:通常由性能监控计数器OMC(Performance Monitor ...
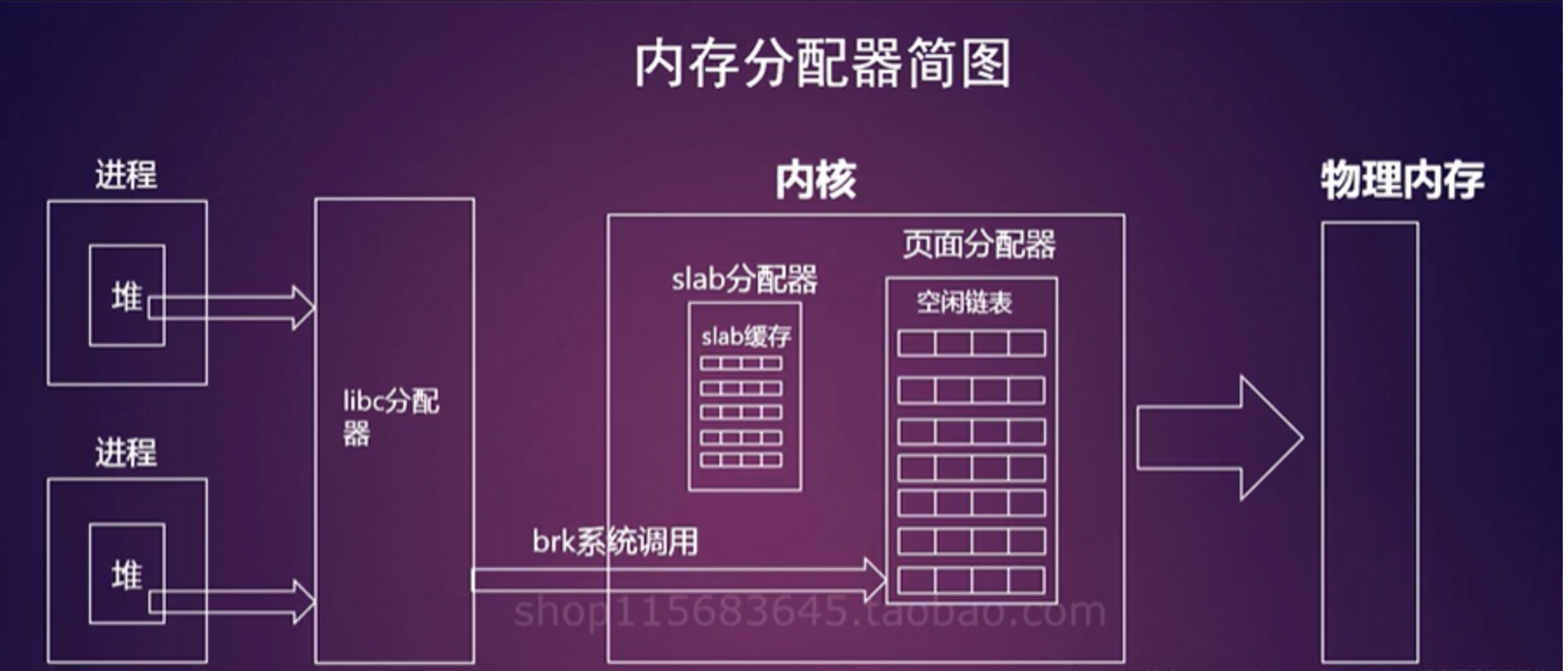
我的内存呢?Linux MemAvailable 如何计算
使用Linux开发是常见的问题是:我的内存呢?怎么只剩这么点了?这是怎么回事呢?
消失的内存
通常我们会用free命令(如下)或Node Exporter + Prometheus 来监控系统的内存。
1234# free total used free shared buff/cache availableMem: 6460324 111876 5577136 75188 771312 6073040Swap: 0
上面的输出中,我们很自然的以为free代表可用内存,所以经常会发现这个值特别低,造成“系统的内存用光”的错觉。在比较新的内核里,会有available一项,它才是“可用内存”。
这里有个小知识,free指的是完全没有被用到的内存,而Linux认为内存不用也是浪费,因此会尽量“多”地把内存用来做各种缓存,提高系统的性能。在内存不够用时,它会释放缓存腾出空间给应用程序。因此早期没有available这项指标时,一般会认为 ...

搭建Android系统模拟器开发环境
自从2022年1月份辞去了Android系统的工作从事自动驾驶行业以来, 已经接近1年了, 在这一年间基本没接触过Android系统的源代码了, 但是Android的设计思想还是在的, 特别是在复杂的自动驾驶系统里面, 很多好的设计和架构都是如出一辙, 所以在好学心的驱使下, 还是打算把Android的aosp源代码给下载下来研究研究, 毕竟Android也是在不停演进, 站在巨人的肩膀上也可以有更多的视野
但是有个问题, 光看源代码可能远远不能满足我的需求, 但是手头上已经没有Android的开发设备了(都换成了Apple设备), 于是就开始倒腾模拟器了, 毕竟模拟器环境搭建好之后开发效率还是挺高的, 话不多说行动起来
Android源代码是通过repo管理的, 一个repo仓库管理了N多了git仓, 首先是环境搭建, 我这边是基于一台联想工作站, 12代i7给Android预留了500G硬盘, 32G内存, 安装的ubuntu 1804系统
源代码环境搭建代码管理工具可以参考这个链接来下载repo:
https://source.android.com/docs/setup/dow ...

Linux性能分析60秒
本文翻译自Netflix技术博客:
Linux Performance Analysis in 60,000 Milliseconds | by Netflix Technology Blog | Netflix TechBlog
Frist 60 Seconds:Summary在本文中,Netfix的性能工程师团队会介绍在一上来的60秒内,在命令行中使用一套优化的性能调研,使用Linux系统中现成的工具。在头60内,你可以运行下面的命令来获取到一个High Level的系统资源利用率和正在运行的进程。首先是最容易理解的,查找一些错误信息和性能饱和度,然后才是资源利用率。饱和度是指一个资源已经超出了他本来应该持有的资源数量,可以理解为一个请求队列的长度,或者等待时间的消耗。
12345678910uptimedmesg | tailvmstat 1mpstat -P ALL 1pidstat 1iostat -xz 1free -msar -n DEV 1sar -n TCP,ETCP 1top
上面有一些工具需要使用到sysstat软件包,在ubuntu系统里面可以使用下面的命令去 ...

C++性能测试工具:google benchmark 进阶
本文将会介绍如何使用模板以及参数生成器来批量生成测试用例,简化繁琐的性能测试代码。
测试对象这次测试的对象是标准的vector,我们在Linux GCC上进行测试。为了写代码方便,开启了C++17的支持。
这次的疑问来自于《A Tour of C++》这本书,在第九章给出了一个很有意义的建议:尽量少用reserve方法。
我们都知道reserve会提前分配足够大的内存来容纳元素,这样在push_back时可以减少内存分配和元素移动的次数,从而提高性能。所以习惯上如果我们知道vector中存储元素的大致数量,就会使用reserve提前进行内存分配,这时典型的“空间换时间”。
而书中给出的理由仅仅是说vector的内存分配器性能已经很高,预分配往往是多此一举,收效甚微。事实到底如何呢?性能问题光靠脑补是不能定位的,所以我们用实验结果说话。
使用模板函数生成测试测试用例的设计很简单,我们定义普通vector和reserve过的vector,然后分别对其添加一定数量的元素(逐步从少到多)测试性能。同时vector本身是泛型容器,所以为了测试的全面性我们需要测试两至三种类型参数。
如果针对每一种 ...




