C++性能测试工具:google benchmark 入门(2)
上一篇中初步体验了google benchmark的使用,本文将进一步深入了解google benchmark的常用方法。
向测试用例传递参数之前我们的测试用例都只接受一个benchmark::State&类型的参数,如果我们需要给测试用例传递额外的参数呢?
举个例子,加入我们需要实现一个队列,现有ring buffer和linked list两种实现可选,现在我们要测试两种方案在不同情况下的性能表现:
1234567891011121314151617181920212223242526272829303132333435// 必要的数据结构#include "ring.h"#include "linked_ring.h" // ring buffer的测试static void bench_array_ring_insert_int_10(benchmark::State& state){ auto ring = ArrayRing<int>(10); for (auto _: state) ...

C++性能测试工具:google benchmark 入门(1)
如果你正在寻找一款C++性能测试工具,那么此文不容错过。
市面上的benchmark工具或多或少存在一些使用上的不方便,那么是否存在一个使用简便又功能强大的性能测试工具呢?答案是google/benchmark。
google/benchmark是一个由Google开发的基于googletest框架的C++ benchmark工具,它易于安装和使用,并提供了全面的性能测试接口。
下面来介绍google/benchmark的安装并用一个简短的例子介绍它的简单实用。
安装google/benchmarkgoogle/benchmark基于C++11标准和googletest框架,所以安装前需要先做一些准备工作。
首先是g++和cmake
1sudo apt install g++ cmake
确保你的g++版本在5.0以上,否则可能不能很好的支持C++11的某些特性。
然后是googletest框架,你可以选择单独安装,不过这里我选择将其作为benchmark源码树的依赖而不单独安装它,因为benchmark在编译安装时需要googletest,但是在使用时并不需要。
选择一个合适的目录 ...

Tip of the Week 126 ‘make_unique’是新的‘new’
随着代码库的扩展,越来越难以了解你依赖的每件事的细节。需要深入的知识无法扩展:我们必须依靠接口和契约来知道代码是正确的,无论是在写还是在审查代码。在许多情况下,类型系统可以用一种通用的方式来提供这些契约。类型系统契约使用的一致性,通过识别在堆上分配的对象存在潜在风险分配或所有权转移的位置,可以更轻松的编写和审查代码。
虽然在C++中,我们可以通过使用纯值来减少动态内存分配的需求,但是有时我们需要对象的声明周期超过其作用域。在动态分配对象时,C++代码应该优先使用智能指针(最常见的std::unique_ptr)而不是原生指针。这提供了关于分配和所有权转移一致性,并在那些需要更仔细审查代码所有权问题的地方留下了更清晰地视觉提示。满足C++14之后,在外部如何分配及异常安全上的副作用只是小事。
关于此的两个关键工具是absl::make_unique()(C++14的std::make_unique的C++11实现,用于免泄漏动态分配)和absl::WrapUnique()(用于包装拥有指向相应std::unique_ptr类型的原生指针)。他们可以再absl/memory/memory. ...
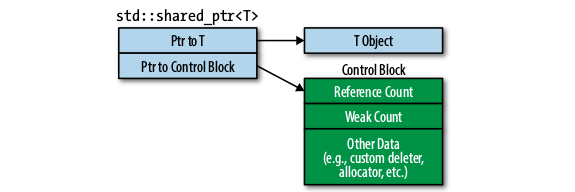
Tip of the Week 123 absl::optional和std::unique_ptr
如何存储值?此贴士讨论了集中存储值得方法。此处我们使用类成员变量作为示例,但是以下的许多同样也适用于局部变量。
1234567891011#include <memory>#include "third_party/absl/types/optional.h"#include ".../bar.h"class Foo { ... private: Bar val_; absl::optional<Bar> opt_; std::unique_ptr<Bar> ptr_;};
作为一个纯对象这是最简单的方法,val_分别在Foo的构造函数的开头和Foo析构函数的末尾被构造和销毁。如果Bar有一个默认的构造函数,那么它甚至不需要显式初始化。
val_使用起来非常安全,因为它的值不能为null。这小出了一类潜在的错误。
但是bar对象不是很灵活:
val_的生命周期基本与它的父Foo对象的生命周期相关,这有时并不是想要的。如果Bar支持移动或交换操作,那么能够通过这些操作替换val_的 ...

Tip of the Week 116 保留多参数的引用
从绘画到图像,从图像到文本,从文本到声音,一种虚构的指针指示、展示、固定、定位、强加引用系统,试图稳定一个独立空间。——米歇尔·福柯创作的这不是一只烟斗
const引用与指向const的指针const引用用作函数的参数,与指向const的指针相比,它有几个优点:它们不能为null。并且很明显该函数没有取得对象的所有权。但是它们有其他的有事会出现问题的差异:它们更加隐式(即在调用点没有任何内容表明我们正在接受引用),并且它们可以被绑定到临时变量。
类中悬空引用的风险将以下类作为示例:
12345678class Foo { public: explicit Foo(const std::string& content) : content_(content) {} const std::string& content() const { return content_; } private: const std::string& content_;};
它看起来是合理的。但是如果我们从stri ...

Tip of the Week 112 emplace与push_back
“我们越少使用我们的力量,它就会越强大。” —— 托马斯 杰克逊
正如你所知(如果不知道,参见TotW 65)
正如你所知道的,C++11引入了一种强大的新方法来讲条目插入到容器中:emplace方法。这些可以让使用任何对象的构建函数在一个容器内原地构建一个对象。这包含移动和拷贝构造函数,因此在你可以使用push或者insert方法时,你可以使用emplace方法代替,而不需要其他修改。
123456std::vector<string> my_vec;my_vec.push_back("foo"); // 这是可行的,因此...my_vec.emplace_back("foo"); // 这也是可行的,并且有相同的结果std::set<string> my_set;my_set.insert("foo"); // 此处相同:任何调用imsert可以被emplace重写my_set.emplace("foo");
这产生一个明显的问题:你应该用哪一个好? ...
Tip of the Week 55 名字计数与unique_ptr
“尽管我们可能以一千种名字来认识他,但是他于我们所有人而言是同一个人。”——圣雄甘地
通俗来讲,值的“名字”是在任意作用域内保持特定数值的任意值类型变量(不是指针也不是引用)。(对于规范准则而言,如果我们说“名字”,实质上我们谈论的是左值。)因为std::unique_ptr的特定行为的要求,我们需要确保在std::unique_ptr中保存的任意值仅有一个名字。
请务必注意,C++委员会为std::unique_ptr选择了一个非常恰当的名字。在任何时候,存储在std::unique_ptr中的任何非空指针值都只能在一个std::unique_ptr中出现;标准库以强制执行此操作来设计的。许多编译代码中使用std::unique_ptr的常见问题能够通过学习如何计算std::unique_ptr的数量来解决:一个名字是可以的,但是相同的指针值对应多个名字则不行。
让我们数一些名字。在每一行,计算在位置(无论是否在作用域内)上包含相同指针的std::unique_ptr并且存在的名字数量。如果你在任何一行发现关于相同指针值的名字多余一个,那是一个错误!
12345678910111 ...

Tip of the Week 65 就地安放
“让我解释一下。不,这太多了。让我总结一下。” —— 埃尼戈·蒙托亚
C++11添加了一种元素插入标准容器的新方法:emplace()方法系列。这些方法直接在容器中创建对象,而不是创建一个临时的对象,然后拷贝或者移动这个对象进容器。避免这些副本对于绝大多数对象而言都是更有效率的,并且在标准容器中存储只移动的对象(例如std::unique_ptr)也会更容易。
旧方法和新方法让我们来看一下两种使用vector的方法,第一个示例使用C++11之前的代码:
12345678910class Foo { public: Foo(int x, int y); …};void addFoo() { std::vector<Foo> v1; v1.push_back(Foo(1, 2));}
使用这些旧的push_bach方法,有两个foo对象被构造:这临时的参数和在vector中由临时对象通过移动构造函数构造对象。
我们能够用C++11中的emplace_back代替,并且只有一个对象在vector的内存中被直接构造。由于“emp ...

共享内存实现—Ring-Buffer
上文有提到,Shared Memory Port用来提供读写的通道,在这个通道中传输的缓存被设计为一个Ring-Buffer,提供P0的发现服务数据读写,或者用户自定义的数据读写。
MultiProducerConsumerRingBuffer这个名字有点长,但是顾名思义,Ring-Buffer被设计为多生产者和多消费者的模式,有如下几个特点:
读写操作都是无锁的
同一个RingBuffer中的数据单元(cell)数目是固定的,数据类型都是一样的
消费者(listener)必须注册获得listener来访问数据
当一个数据单元(cell)被推送到buffer,这个数据单元的计数值为当前注册的listener个数
当某个数据单元(cell)被所有的listener都取出之后,这个数据单元会被释放掉
MultiProducerConsumerRingBuffer::Cell1234567891011121314151617181920class Cell { public: const T& data() const ...

FastDDS进程间内存共享
概述
本文描述了一个通过共享内存实现进程间通信模型,通过这个模型,不同的软件组件可以进行数据交换。这个模型的目标是提供了一种基于共享内存的数据传输层,来适配一个实时订阅发布的DDS(Data Distribution Service)框架。
上下文eProsima是接收到了一个商业上的方案通过共享内存传输来改进FastRPTS产品。下面是这一块列出的一些目标。
通过标准的网络传输的改进
减少操作系统内核的系统调用:这对于UDP/TCP是不可避免的(甚至在loopback的设备上)
大数据传输支持:网络传输往往需要把大数据切片传输
避免数据的序列化和反序列化过程:在异构网络中是不可能的,但是在进程间共享内存中是可行的
减少内存拷贝:共享内存可以实现零拷贝,客户端可以直接拿到共享buffer的指针进行访问
目标
提高进程间通信的性能
创建一套可移植的共享内存库(Windows/Linux/MacOS)
文档
测试
示例代码
架构设计理念
Segment:一块固定大小的共享内存,不同的进程可以访问。共享内存快有一个全局的名称,所以任何一个知道这个名称的进程都可以打开这块内存,然后映射到 ...




